
via:
Cerebras brings instant inference to Mistral Le Chat - Cerebras
Cerebras January update: Fastest DeepSeek R1-70B, Mayo Clinic genomic model, Davos appearance, and more! Learn how we're accelerating AI with real-time inference, machine learning, and case studies.
 cerebras.ai ↗
cerebras.ai ↗ This inference service is based on their Wafer Scale Engine:
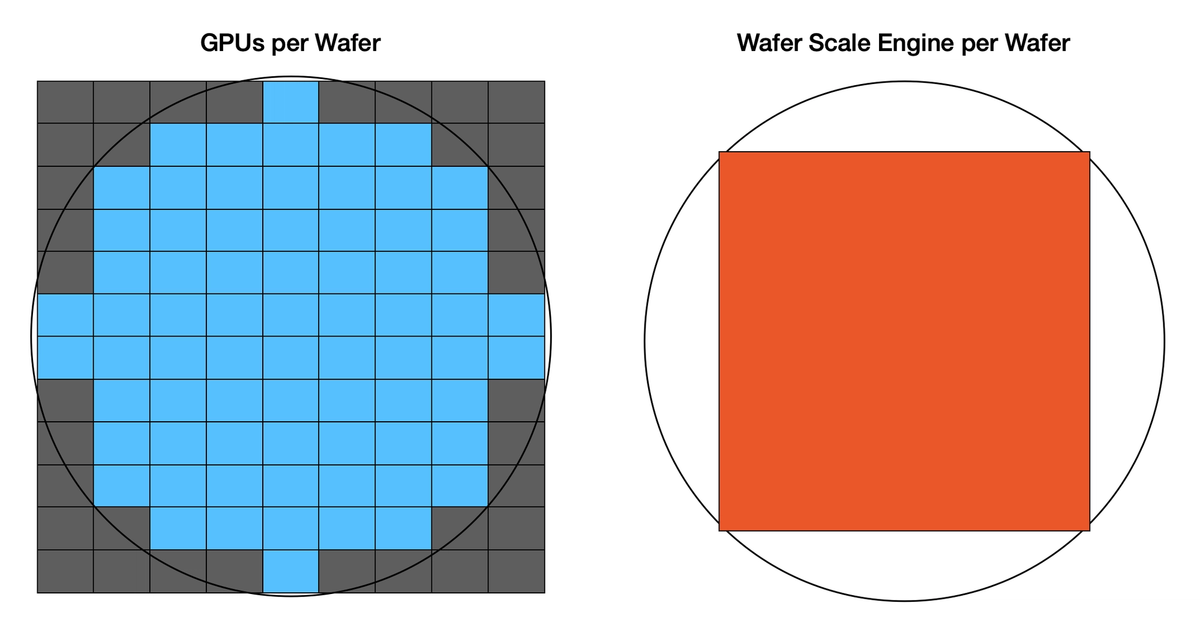
via:
100x Defect Tolerance: How Cerebras Solved the Yield Problem - Cerebras
Cerebras is the go-to platform for fast and effortless AI training. Learn more at cerebras.ai.
 cerebras.ai ↗
cerebras.ai ↗